
スタッフブログ

ブログに書いたつもりが下書きのままパソコン内に記事が眠ってて焦った龍司です。
2013年10月22日にEngineYardさんで開催されたSendGrid Nightに参加してきました。
EnginYardさんでは、定期的に1つのPaaSを掘り下げた勉強会を開催していこうと考えてるそうで、その取り組みが「○○ Night」みたいです。
1回目はサーバ監視サービスの「NewReric」をとりあげた「NewReric Night」を開催、2回目はメール配信サービスの「SendGrid」をとりあげる「SendGrid Night」ってことでした。(今後どんな○○Nightが開催されるか楽しみですね。)
以前EngineYardの安藤さんにSendGridの存在を教えてもらっていて興味をもったんですが、今回の勉強会に参加してみるまで自分がなんでSendGridに興味もったのかをすっかり忘れてました(^^;
それが参加してみてやっと何故興味をもったか思いだすことができました。
何故興味をもったか?
それは「メールの大量配信をちゃんと行うのはすんごいめんどくさいこと」だったからです。
会員制のWebシステム開発を何度もやってると中にはメールを大量配信するケースも出てきます。これをまともに実行できるようにするのがとてもめんどくさかったんですね。
メール配信をちゃんとやろうとすると、なにがめんどくさいか
SendGridNightでも話しがあったのですが、今やメールの9割が迷惑メール。各プロバイダや携帯キャリア、メールソフトそれぞれが迷惑メール対策をあれこれ実施しています。
そのおかげで迷惑メールに触れる機会が減ってるんですが、ちゃんとしたメール配信をしようとすると、この各種の迷惑メール対策でフィルタリングされないように、送信側もあれこれ設定したり、配信ペースを押さえたりと面倒なことがいっぱいでてきます。
さらにサーバのスペックの問題も発生します。メール送信って他のサーバとの通信が発生するのでサーバにけっこう負担かけるんですよね。それにあわせてサーバスペックあげると、メール配信以外の普段ではオーバースペックでハイコストの原因になっちゃうし、スペックさげるとメール配信がいつまでも終わらないなんてことが起こったり、けっこうムキーーーってなったりします。
エラーメールの対処をどうするかってのも頭の痛い問題です…
ほんと、送ったメールがちゃんと届くようにする って結構大変なことだったのを勉強会を通してよーーーーっっっく思いだしましたよ…
で、SendGrid。
SendGridはWebサービス、Webサイトをつくってるときに発生するこういう「めんどくせーーー!!」と叫びたくなるメール配信系をうまいことやってくれるサービスなわけですね。
というわけで基本的なメール配信はもちろん問題なくできるようになってますが、それだけでなくプラスアルファでいろいろ便利そうなサービスになってます。
SendGridが便利そうなポイント
自分でメールサーバをたてる大変さから解放されるのが一番のポイント。
他の便利ポイントとしては
- 送信ログの確認ができる
- 配信されたか拒否されたかちゃんとわかります。
- ParseAPI使うと受信メールをきっかけにWebへメール内容をPOSTなんてこともしてくれる
- SMTP API使うと一度に1000通ぐらい送信とか宛名の置換とかもできるそうです
- 無料で毎月6000通まで送信OKらしいので、メール送信テスト時にコストかからんのもいいです
ってあたりが個人的にはヒットでした。
最近ちょっとWindowsAzureをうまいこと利用できないか試行錯誤してるんですが、WindowsAzureはメール送信できないってことで早速SendGridの無料プランをちょっと使わせてもらいました。
これをきっかけにちょこちょこ利用できたらなぁと思ってます。
その後オープンソースと関わるようになってから「CVS」「Subversion」を使うようになりました。
そして今使ってるバージョン管理システムが「Git」です。といってもあれこれ検討してSubversionからGitへうつったわけでなく、周囲の開発者さんたちが「Git便利!」って言ってほぼ全員Gitへ移行してたり、XOOPS CubeのリポジトリがSubversionからGitHubへ移行したりとなって、ようやく自分でも使い始めた格好です。
そうやって使い始めたGitですが、Subversionと同じ程度には使えるようになってきたのですが、他の開発者さんの使い方を観察するともっと色々便利なコマンドや使い方があるようなので、一通りざっくり把握してみようと思って、「Gitポケットリファレンス」をパラパラと読んでみました。

開発中の様々な要望に応える方法がほとんどありそう
というわけで「Gitポケットリファレンス」を毎朝数ページずつ読んでみたんですがすごいですねGit!
Subversion使ってたときに「あー、○○したいんだけど、うまい方法ないんだよなぁ」って思うことがほぼ解決してます。
というか、開発中に遭遇するバージョン管理にまつわるあれこれに対応する方法が網羅されてそうな印象です。
たとえば 、ファイルの各行の変更履歴を出力する "git blame"
プログラムの不具合が発生したときにプログラムコードを追っかけてると「あれ?なんでこんな処理してるんだろ?」って疑問に感じるコードにあたることがあります。
そんなときに過去バージョンをチェックして**いつごろその処理が書かれたのか**を調べて、関連するRedmineのチケットや議事録をもとに「そもそもどう意図で行われた変更か」というのを調査して、意図にあったコードになってるか確認します。
この「いつごろその処理が書かれたのか」を調べるのがgit blameを使うと簡単にできちゃうんですよね。
git blameで「このファイルの何行目から何行目はいつ更新された?」を調べられるので先ほど書いたシチュエーションではめっちゃ役立ちそうです。
この git blameをはじめとしてほんとかゆいところに手が届くバージョン管理システムになってますね。
というわけで、最近gitを使ってみた感触やこの本から得られた知識から考えてもこれからのバージョン管理システムは git がよさそうだなと思いました。
そんな要望のうち予算内でシステム化できることでも、あえてシステム化しないことを提案することもあります。
私がシステム化をお勧めしないのは、頻度が少ないのに複雑な処理が必要にな業務についてです。
・年に数回しか行わない
・手順が定まってない
・毎回ちょっとずつ違うやり方でやっている
こういう業務をシステム化すると、
・滅多に使わない機能なのに工数(開発費用)が増える
・数回使っただけで機能改修しないと使えなくなる
・他の良く使う機能が、滅多に使わない機能の複雑な制約にひっかかって使いにくくなる
なんてことが良く発生します。
だから予算があっても「滅多に使わない」「やけに複雑」な業務については
システム化するか慎重に判断することをおすすめしています。

SSHにログインしようとするとToo many authentication failuresと言われる
MacのターミナルでSSHにログインしようとすると次のようなメッセージが出てログインできません。
Received disconnect from XXX.XXX.XXX.XXX: 2: Too many authentication failures for *username*
このように解決しました
Macのターミナルを起動
$ ssh-add -D $ open ~/.ssh/config # お使いのエディタがあればそれでひらいてください。 # configファイルが無ければ作ってください。テキストでいいです。
configファイルの最初に以下の行を追加
IdentitiesOnly yes
svn upするとsvn: access to '*url*' forbiddenと言われる
svn upしようとすると、svn: access to '*url*' forbiddenと言われて、アップデートが失敗しました。 他のマシンで同じようにsvn upしたらできたので、問題が起きたPCの問題だと分かりました。
このように解決しました
前回、svn upしたユーザが違っていたのが問題だったようです。 前回ユーザ suin で sudo svn up していたのに、今回は root で svn up しようとしました。 そこで、suinユーザで sudo svn up したら、問題なくアップデートできました。
MySQLには遅いクエリーを改善するために、指定した秒数以上かかったクエリーをログに取っておいてくれる機能があります。それをスロークエリーログといいます。この記事では、スロークエリーログを有効にして、実際に作られたログを確認するところまで順を追って説明します。
ひとまずrootになる。
sudo su - root # とか su - root
MySQLの設定ファイルを編集します。
vim /etc/my.cnf # vim: command not foundな人は vi /etc/my.cnf
iとタイプして編集モードへ。
slow_query_log=1 # スロークエリーログを有効にします。ONとかOnと書いても有効にならないので注意。 slow_query_log_file=mysql-slow.log # フルパスじゃないとたぶん、datadirにできます。 long_query_time=1 # 秒数で指定。この例では1秒以上かかるクエリはログに残る
escキーを押して、:wqとタイプ後Enterで上書き保存
MySQLの再起動を忘れずに。
/etc/rc.d/init.d/mysqld restart
MySQLにログインしてみよう。
mysql -u root # とか mysql -u root -p
2秒かかるクエリーを実行してみる。
mysql> SELECT SLEEP(2); +----------+ | SLEEP(2) | +----------+ | 0 | +----------+ 1 row in set (2.00 sec)
MySQLから抜けます。
mysql> exit
slow_query_log_fileがあるディレクトリに移動。
cd /var/lib/mysql/
中身を見てみよう。
cat mysql-slow.log # Time: 101021 13:04:49 # User@Host: root[root] @ localhost [] # Query_time: 2.002632 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0 SET timestamp=1287633889; SELECT SLEEP(2);
ちゃんとログが取れてるのが確認できました。
MySQLのInnoDBはトランザクションが使えたり、行ロックが使えたりして、データの整合性の点でMyISAMに比べて優れています。 業務系アプリになると、データの整合性が重視されることも多く、トランザクションを使うことも増えます。
今回、そのトランザクションを使っていて、思いもよらないクエリがきっかけで、テーブルにロックが掛かってハマりました。
テーブル構造はこのような感じ...。
CREATE TABLE `working` ( `id` int(11) NOT NULL AUTO_INCREMENT, `col` int(11) NOT NULL DEFAULT '0', PRIMARY KEY (`id`), KEY `col` (`col`) ) ENGINE=InnoDB;
もう一個まったく同じテーブルを作ります。
CREATE TABLE `backup` LIKE `working`;
workingにデータを入れます。
INSERT INTO `working` (`col`) VALUES ('1'), ('2'), ('3');
SELECT * FROM `working`;
+----+-----+
| id | col |
+----+-----+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+----+-----+
ちなみに、分離レベルを見ておきます。
SELECT @@tx_isolation; +-----------------+ | @@tx_isolation | +-----------------+ | REPEATABLE-READ | +-----------------+
さて、もう察しが付いているかもしれませんが、これからworkingからbackupにデータを移すクエリを実行したいと思います。
クライアント1
クライアント1は、BEGINしてトランザクションを開始し、INSERT INTO t SELECT ... FROM s WHERE...を使って、データコピーのクエリを実行します。
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO `backup` (`col`) SELECT `col` FROM `working` WHERE `col` = 3;
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
この処理は一瞬で終わりますが、COMMITやROLLBACKせず、トランザクションはそのままにしておきます。
クライアント2
クライアント2では、普通にworkingにINSERTします。
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM `backup`;
Empty set (0.00 sec)
mysql> INSERT INTO `working` (`col`) VALUES ('4');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
まず、backupテーブルはまだ空です。これはクライアント1がコミットせずトランザクションを維持しているからです。しかし、ここでworkへのINSERTが長く待たされます。挙句に、「Lock wait timeout exceeded」というエラーが出て、クライアント2のトランザクションが終了してしまいます。
一見すると、とても奇妙な挙動です。クライアント1は、サブクエリーでworkingテーブルにSELECTしているだけです。UPDATEやSELECT ... FOR UPDATEをかけているわけではないからです。
ところが、良く調べてみると、INSERT INTO SELECT FROMの形でSELECTされたテーブルにロックが掛かることがあるとマニュアルに書いてありました。
INSERT INTO T SELECT ... FROM S WHERE ... は T に挿入された各行に、ギャップロックなしの排他インデックスレコードロックを設定します。innodb_locks_unsafe_for_binlog が有効であるかトランザクション遮断レベルが READ COMMITTED である場合には、InnoDB は S での検索を一貫性読み取り (ロックなし) として行います。それ以外の場合、InnoDB は S から取得した行に共有ネクストキーロックを設定します。InnoDB は後者の場合にロックを設定する必要があります。バックアップからの前進復旧では、すべての SQL ステートメントはそれが元々行われたのとまったく同じ方法で実行されなければいけません。
これを読む限りでは、workingテーブルにネクストキーロックがかかってしまったようです。注目して欲しいのは、クライアント1のクエリの`col` = 3と、クライアント2の(`col`) VALUES ('4')です。ネクストキーロックの範囲や発動条件はよく調べていないのでなんとも言えませんが、colの数字が3と4で隣り合っています。これによってロックが発動したようです。
ためしに、下のように隣接していない場合はロックが掛かりません。
# クライアント1 mysql> BEGIN; Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO `backup` (`col`) SELECT `col` FROM `working` WHERE `col` = 1; Query OK, 1 row affected (0.00 sec) Records: 1 Duplicates: 0 Warnings: 0 # クライアント2 mysql> BEGIN; Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO `working` (`col`) VALUES ('4'); Query OK, 1 row affected (0.00 sec)
また比較として、単なるSELECTやINSERTでは、ロックはかかりません。
# クライアント1
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO `working` (`col`) VALUES ('3');
Query OK, 1 row affected (0.00 sec)
# クライアント2
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO `working` (`col`) VALUES ('4');
Query OK, 1 row affected (0.00 sec)
もし、以下の条件に当てはまる処理は、INSERT INTO SELECT FROMのサブクエリを独立させてPHPで結果をINSERTに渡すような実装にしたほうが良いかもしれません。
- workingは頻繁にINSERTされる。(そして待たされたり、タイムアウトしては困る。)
- INSERT INTO SELECT FROMのあるトランザクションが非常に長い。
- クライアント2のINSERTはクライアント1のトランザクションに全く関係ないデータである。
余談
今回はトランザクションにはまりましたが、ROLLBACKは便利そうです。大量のテストデータとテストパターンがあって、毎回DBをリストアしてテストしなおすような計画では、テストが完了するごとにROLLBACKすると良さそうです。一瞬でDBがもとに戻ります。
(前提としてサーバーにSSHログイン出来ることが必要です)
解凍
まず、頻度が高そうな解凍からです。自分のPCにあるtar.gz形式のファイルをサーバー上にアップロードします。
WinSCPを起動して接続先の一覧から保存したセッションを選択してログインします。
2ペインで表示してローカルのPC側からサーバー側へへファイルをドラックアンドドロップするとファイルをアップロードできます。
また、ファイルエクスプローラーやデスクトップに置いたファイルをドラックアンドドロップしてもアップロードできます。
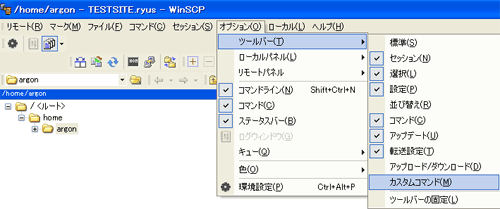
次に、設定をします。
オプション>ツールバー>カスタムコマンドをチェックをつけてカスタムコマンドを表示させます。

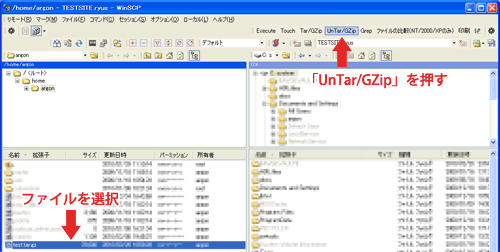
解凍は解凍したいtar.gzファイルを選択して「UnTar/GZip」をクリックします。
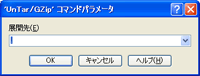
展開先(解凍先)を入力するウインドウが表示されます。
デフォルトのまま「OK」をクリックすると、ファイルをアップロードした場所と同階層に解凍されます。
展開先の欄にフォルダ名を指定すれば、そのフォルダ下に解凍されます。
展開先(解凍先)を入力するウインドウ
解凍完了

圧縮
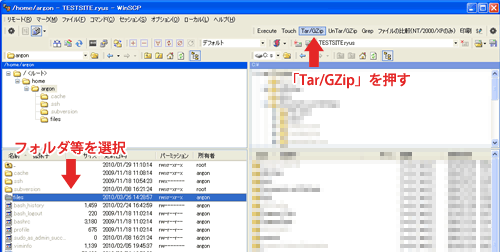
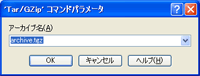
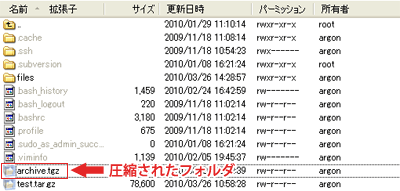
圧縮する時は解凍する時と同様にWinSCPの画面で圧縮したいフォルダ等を選択して今回は「Tar/GZip」をクリックします。アーカイブ名を聞かれるウインドウが表示されます。
デフォルトは「archive.tgz」です。名前を変更したい時はここの入力欄で変更します。
拡張子は「tgz」から「tar.gz」に変更しても大丈夫です。
アーカイブ名を聞かれるウインドウ
圧縮完了
以上になります。
サーバーに大量のファイルをアップロードすると、どうしても時間がかかってしまいますし、回線次第によっては途中で接続が切れる事もあります。
今回の紹介したようにSSHが使える環境でしたら、tar.gzの形式でアップロードして、サーバー上で解凍するの方が時間もかなり短くなりますし作業もより確実です。
WinSCPとは
http://winscp.net/eng/docs/lang:jp
WinSCPダウンロード
http://winscp.net/eng/download.php

今日HTML5の新機能であるWeb Databaseを仕事で使えないかなーと調べてみたので、
簡単に使い方をコードで紹介したいと思います。
<script>
var db = openDatabase("sample", "1.0", "Sample database", 1024 * 1024);
function createTable() {
db.transaction(function(tx) {
tx.executeSql(
"CREATE TABLE IF NOT EXISTS users( id INTEGER PRIMARY KEY AUTOINCREMENT, name VARCHAR(64) NOT NULL);",
null,
insertData,
function() {
alert("CREATE 失敗");
}
);
});
}
function insertData(tx) {
tx.executeSql(
"INSERT INTO users(name) VALUES(?);",
["hamaco"],
findData,
function() {
alert("INSERT 失敗");
}
);
}
function findData(tx, rs) {
tx.executeSql(
"SELECT * from users WHERE id = ?",
[rs.insertId],
function(tx, rs) {
document.body.innerHTML = rs.rows.item(0)["name"];
},
function() {
alert("SELECT 失敗");
}
);
}
createTable();
</script>
上記コードを実行すると、Safariのデータベースデバッグ用の画面で以下の様にデータが入っているのを確認することができます。

CREATE,INSERT,SELECTの3つを行なっているだけですが、executeSqlメソッドが非同期で動作する為、このように面倒くさいコードになってしまいます。
ただ、現在Web Databaseが動作するのはSafari4しかなく、他のブラウザでは動作しないので結局仕事には使えませんでした。
たいていは、「CTRL+Cを押して、コマンドを中断してやりなおす」か、「BSキーを適度に連打して、再度入力」という方法をとると思います。
が、一旦中断するのは面倒だし、BSキーもどれだけ押せばいいかわからないので、不便です。
こういった場合は、「CTRL+uを押す」と、入力中の内容をすべて削除できます。
間違えたかも。と思った時はあわてずにCTRL+uを押して再度入力すると、あの入力内容が見えない画面も怖くなくなると思います。

こんにちわ。 なおとです。
開発では、なにごともやってみて初めて分かるということがあるものです。 今回は、あるコンテンツに対して「HEADリクエストを送って存在確認をする」、というスクリプトを(PHPで)書いた時の話です。
マニュアルにはレスポンスが正常な場合(200 OK)の例が掲載されています。 これが、リダイレクトするコンテンツの場合には、少々様子が異なってきます。
結果を書いてしまうと、「get_headers()はリダイレクトを辿って複数のリクエストを行う」ということを知りました。 私は「HTTP HEADの結果に係わらず、1回だけリクエストして、その結果を返す」という動作を(勝手に)想像していたのですが、違いました。
動作を確認するために以下のような、リダイレクトを数回繰り返すサンプルを用意しました。(redirect.php)
<?php
$req = $res = $_SERVER['REQUEST_URI'];
if (preg_match('/[^\w\:\/\.]/i', $req)) {
echo 'wrong request.';
} else {
if (strpos($req, '.php') === (strlen($req) - 4)) {
$res = $res . '/';
}
if (!strpos($req, '1111')) {
$res = $res . '1';
header('Location: ' . $res);
} else {
echo htmlspecialchars($req, ENT_QUOTES, 'UTF-8');
}
}
これを、get_headers()を使って結果を見ます。(別のスクリプトです)
<?php
var_dump(get_headers('http://localhost/redirect.php', 1));
その結果が以下になります。
※分かりやすくするために、一部を編集しました
array
0 => string 'HTTP/1.1 302 Found' (length=18)
1 => string 'HTTP/1.1 302 Found' (length=18)
2 => string 'HTTP/1.1 302 Found' (length=18)
3 => string 'HTTP/1.1 302 Found' (length=18)
4 => string 'HTTP/1.1 200 OK' (length=15)
'Date' =>
array
0 => string 'Tue, 13 Oct 2009 06:38:51 GMT' (length=29)
1 => string 'Tue, 13 Oct 2009 06:38:51 GMT' (length=29)
2 => string 'Tue, 13 Oct 2009 06:38:51 GMT' (length=29)
3 => string 'Tue, 13 Oct 2009 06:38:51 GMT' (length=29)
4 => string 'Tue, 13 Oct 2009 06:38:51 GMT' (length=29)
'Server' =>
array
0 => string 'Apache/2.2.8 (Ubuntu) PHP/5.2.4-2ubuntu5.7 with Suhosin-Patch' (length=xxx)
1 => string 'Apache/2.2.8 (Ubuntu) PHP/5.2.4-2ubuntu5.7 with Suhosin-Patch' (length=xxx)
2 => string 'Apache/2.2.8 (Ubuntu) PHP/5.2.4-2ubuntu5.7 with Suhosin-Patch' (length=xxx)
3 => string 'Apache/2.2.8 (Ubuntu) PHP/5.2.4-2ubuntu5.7 with Suhosin-Patch' (length=xxx)
4 => string 'Apache/2.2.8 (Ubuntu) PHP/5.2.4-2ubuntu5.7 with Suhosin-Patch' (length=xxx)
'X-Powered-By' =>
array
0 => string 'PHP/5.2.4-2ubuntu5.7' (length=20)
1 => string 'PHP/5.2.4-2ubuntu5.7' (length=20)
2 => string 'PHP/5.2.4-2ubuntu5.7' (length=20)
3 => string 'PHP/5.2.4-2ubuntu5.7' (length=20)
4 => string 'PHP/5.2.4-2ubuntu5.7' (length=20)
'Location' =>
array
0 => string '/redirect.php/1' (length=15)
1 => string '/redirect.php/11' (length=16)
2 => string '/redirect.php/111' (length=17)
3 => string '/redirect.php/1111' (length=18)
'Content-Length' =>
array
0 => string '0' (length=1)
1 => string '0' (length=1)
2 => string '0' (length=1)
3 => string '0' (length=1)
4 => string '18' (length=2)
'Connection' =>
array
0 => string 'close' (length=5)
1 => string 'close' (length=5)
2 => string 'close' (length=5)
3 => string 'close' (length=5)
4 => string 'close' (length=5)
'Content-Type' =>
array
0 => string 'text/html' (length=9)
1 => string 'text/html' (length=9)
2 => string 'text/html' (length=9)
3 => string 'text/html' (length=9)
4 => string 'text/html' (length=9)
get_headers()の第2引数に「1」をセットしなかった場合は、もっと混沌とした結果になっていましたが、省略します。
それと今回は、自分自身にリダイレクトするスクリプトで実験しました。 異なるサーバ/スクリプトに跨ってリダイレクトを辿った場合は、レスポンス・ヘッダーの内容も異なると思われますので、もう少し複雑な結果になります。
これを受けて、「Locationの結果、行き着くコンテンツ」は次のように取得できることがわかります。 ただし、URLの解決(絶対URLに直す処理)は端折っています。 あと実際のコードでは、エラー処理など適宜しています。
<?php $url = 'http://localhost/redirect.php'; $headers = get_headers($url, 1); $location = $headers['Location']; if (is_array($location)) { $location = array_pop($location); } if ( (strpos('/', $location) === false) and (strpos('http', $location) === false) ) { $location = dirname($url) . '/' . $location; } echo "original: {$url} \n redirected: {$location} \n";
以上です。


